scrapy 是一个爬虫框架,首先了解这个框架的基本结构,然后针对实际使用进行学习
- 官方文档
- []
框架结构
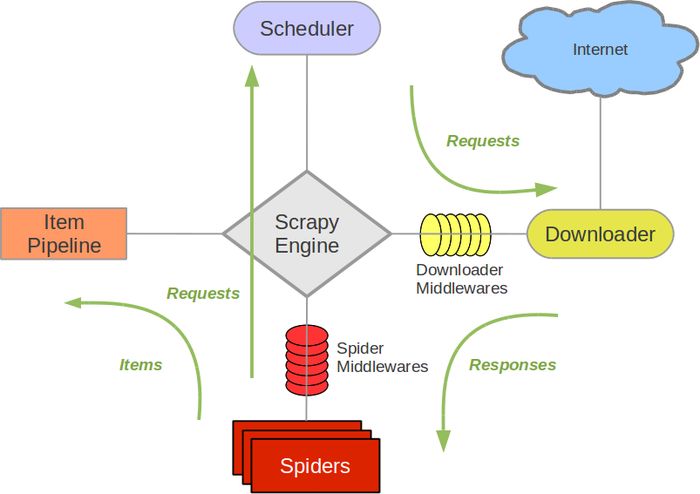
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
相当于大脑
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流:
引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
引擎向调度器请求下一个要爬取的URL。
调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
创建爬虫项目
scrapy startproject scrapyspider
会创建以下目录和文件:
scrapyspider/
scrapy.cfg
scrapyspider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
- scrapy.cfg: 项目的配置文件。
- scrapyspider/: 该项目的python模块。之后您将在此加入代码。
- scrapyspider/items.py: 项目中的item文件。
- scrapyspider/pipelines.py: 项目中的pipelines文件。
- scrapyspider/settings.py: 项目的设置文件。
- scrapyspider/spiders/: 放置spider代码的目录。
案例编写爬虫
执行爬虫其实是执行爬虫项目里面的Spider项目,所以首先要创建一个Spider项目。
scrapy genspider bule_item www.tenholes.com
import scrapy
from scrapy.http import Request
from ..items import BluesItem
class BluesItemSpider(scrapy.Spider):
name = 'blues_item'
allowed_domains = ['www.tenholes.com']
start_urls = [
'http://www.tenholes.com/tabs/catelist?id=1&page={}'.format(i)
for i in range(1, 29)
]
def start_requests(self):
cookies = self.get_cookies()
for url in self.start_urls:
yield Request(url, cookies=cookies, dont_filter=True)
def parse(self, response):
content = response.xpath('//div[@class="ms-list"]/a')
for each in content:
item = BluesItem()
item['name'] = each.xpath(
'./p[@class="ms-tit ellipsis"]/text()'
).extract_first()
item['music_url'] = each.xpath('./@href').extract_first()
yield (item)
def get_cookies(self) -> dict:
cookies_str = open('cookie', 'r').read().strip()
# 将字符串转换为字典
cookies = {}
for line in cookies_str.split(';'):
name, value = line.strip().split('=', 1)
cookies[name] = value
return cookies
在parse中也可用使用yield scrapy.Request来请求下一个页面。
Request中还可以定义callback来指定回调函数,meta来传递参数。
设置 output 格式为 utf-8
FEED_EXPORT_ENCODING = 'utf-8'
对图片和文件进行下载
在使用测试的时候,发现MediaPipeline无法进行指定file_path,导致无法下载后无法保存。只能用FilesPipeline和ImagesPipeline
首先要在settings.py中定义两个东西:
FILES_STORE或者IMAGES_STORE路径ITEM_PIPELINES需要使用Pipeline
ITEM_PIPELINES = {
'blues.pipelines.SongImageDwonloadPipeline': 300,
'blues.pipelines.SongSfMp3DownloadPipline': 301,
}
IMAGES_STORE = 'download_file'
FILES_STORE = 'download_file'
然后再在pipelines.py文件中定义需要下载的内容。
from scrapy.pipelines.images import ImagesPipeline
from scrapy.pipelines.files import FilesPipeline
from scrapy import Request
from .func import cookies
class SongImageDwonloadPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
yield Request(
item['song_image_url'], meta={'name': item['name']}, cookies=cookies
)
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None, *, item=None):
name = request.meta['name']
return name + '/song.jpg'
class SongSfMp3DownloadPipline(FilesPipeline):
def get_media_requests(self, item, info):
yield Request(
item['song_mp3_sf_url'], meta={'name': item['name']}, cookies=cookies
)
def file_path(self, request, response=None, info=None, *, item=None):
name = request.meta['name']
return name + '/示范.mp3'
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 365433079@qq.com