介绍
什么是DIP(The Dependency Inversion Principle 依赖反转原则), 他的定义是什么
一、高级模块不应该依赖于低级模块,两者都应该依赖于抽象。
二、抽象不应该依赖于细节,相反,细节应该依赖于抽象。
所以通常的模式是业务逻辑 -> 中间层 -> 数据逻辑
第1部分: 构建支持领域建模的体系结构
我们发现,许多开发人员在被要求设计一个新系统时,会立即开始构建一个数据库模式,而对象模型则是事后才想到的。这就是一切开始出错的地方。相反,行为应该放在第一位,并驱动我们的存储需求。毕竟,我们的客户并不关心数据模型。他们关心系统做什么; 否则他们只会使用电子表格。
通过 TDD构建富对象模型,提出了四个关键的设计模式:
- 仓库模式,对持久存储概念的抽象
- 服务层模式来清楚地定义我们的用例开始和结束的位置
- 提供原子操作的工作单元模式
- 加强数据完整性的聚合模式


1. 域建模 Domain Modeling
单元测试的名称描述了我们希望从系统中看到的行为,我们使用的类和变量的名称取自业务术语。我们可以向非技术人员同事展示这段代码,他们会同意这正确地描述了系统的行为。
Domain Model 也就是核心模型,是在剥离了数据细节,专注于处理业务逻辑的地方,这里也是最常被修改的地方。
要清楚,剥离了数据后,所有的逻辑都是在核心模型里面进行的。
那么就要思考一些问题。
- 在一开始设计的时候,首先就是对这一块代码的试试,并且是以测试驱动的,那么数据怎么来? 怎么测试
- 哪些是真正的业务逻辑,哪些是底层逻辑?
在书中给出了使用@dataclass来建立一个Value Object的方式来分配了一个不可变动的数据容器。
在Domain Model中需要保持良好的注解习惯,方便阅读。
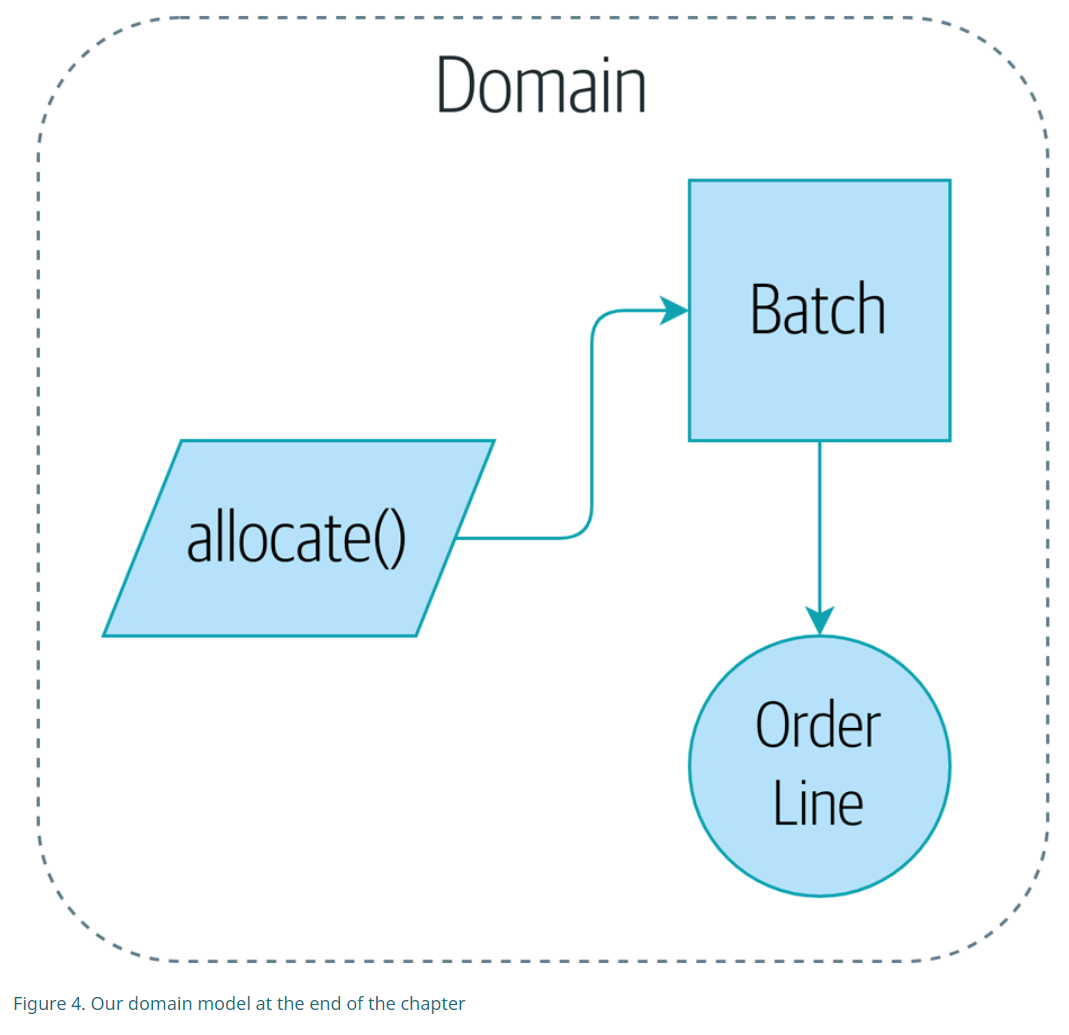
2. 库模式 Repository Pattern
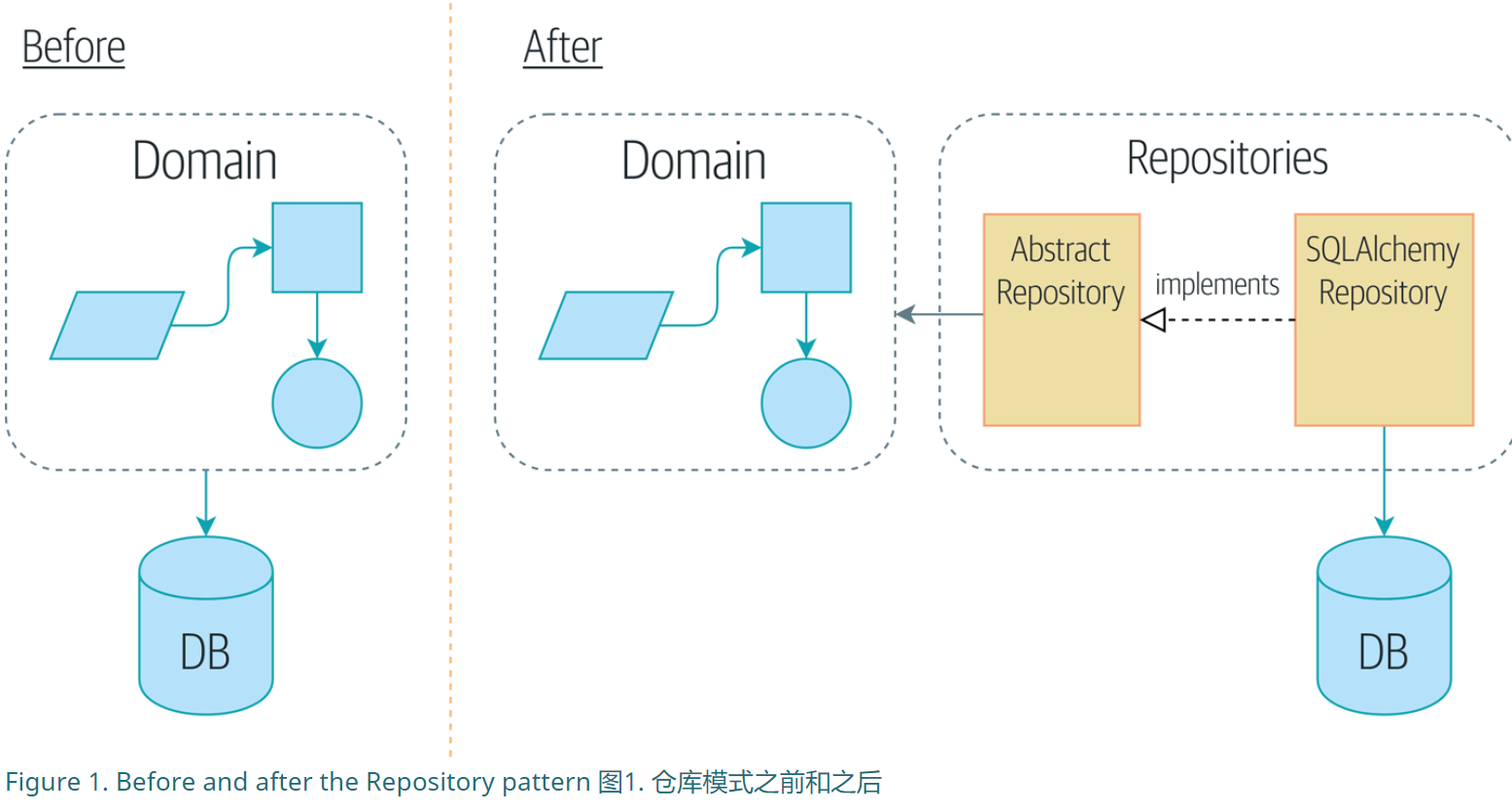
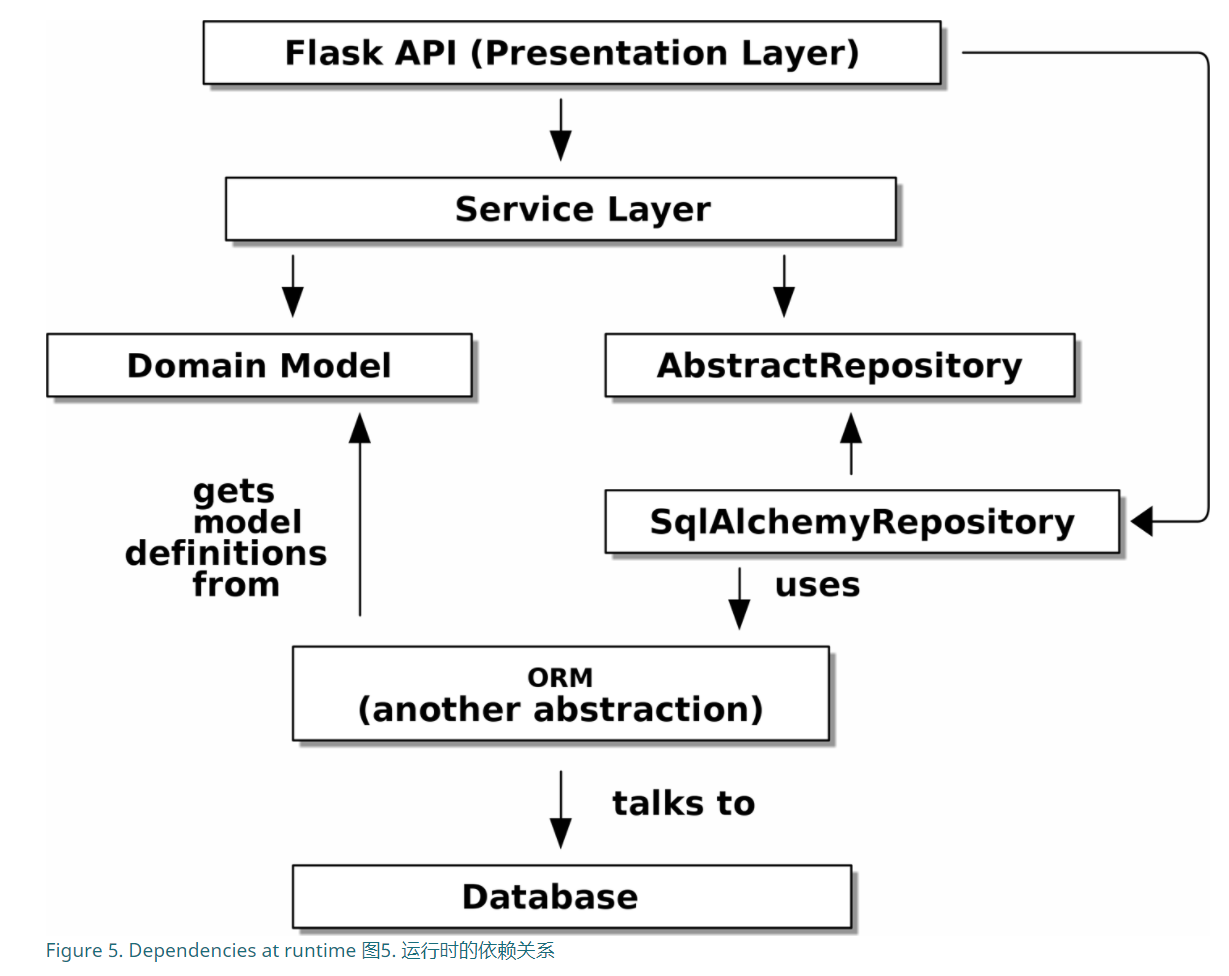
如上所示的模型,领域模型不依赖于数据层,而是反过来的依赖关系。
这种设计模式叫做依赖反转原则(DIP)。
还有一个叫做控制反转(IoC),说的是原本A控制B的流程变成了B由外部容器控制。
那么这样就需要解决一个问题,如何让Domain调用数据层的内容。所以就有了仓库这样的适配器。
按照我目前的理解,适配器其中一个作用就是将存在DB中的Domain实例提取出来,然后给到Domain Model中执行。
# load all batches from the DB
batches = session.query(Batch).all()
# call our domain service
allocate(line, batches)
我们坚持定义接口是我们程序和我们抽象出来的东西之间有一个约定。对于调用方并不关心一个方法究竟是怎么实现的。我们只想知道这个方法能给我们带来什么。
- 其中用到了数据库的ORM技术,即把表和类关联起来,重点是session和mapper。
在内存中建立数据库的方法是:
def in_memory_db():
engine = create_engine("sqlite:///:memory:")
metadata.create_all(engine)
return engine
仓库模式的一个优势就是可以方便的使用假数据做测试,因为可以在test中建立一个FakeRepository仓库来模拟测试。
3. 关于耦合和抽象的概念
当我们必须从基本原则出发来解决问题时,我们通常会尝试编写一个简单的实现,然后重构以获得更好的设计。我们将在整本书中使用这种方法,因为这是我们在现实世界中编写代码的方式: 从问题的最小部分的解决方案开始,然后迭代使解决方案更加丰富和更好地设计。
我们将在这里运用一个技巧,我们将在本书后面大规模运用这个技巧。我们要把我们想做的和怎么做的区分开来。
一般来说,顶级函数就是在输入后将复杂的逻辑交到低级函数,低级函数经过复杂处理得到如何做后,交给顶级函数,然后顶级函数根据怎么做来执行任务。
这样一来,测试的时候,做低级函数的测试就更加方便。
4. 服务层
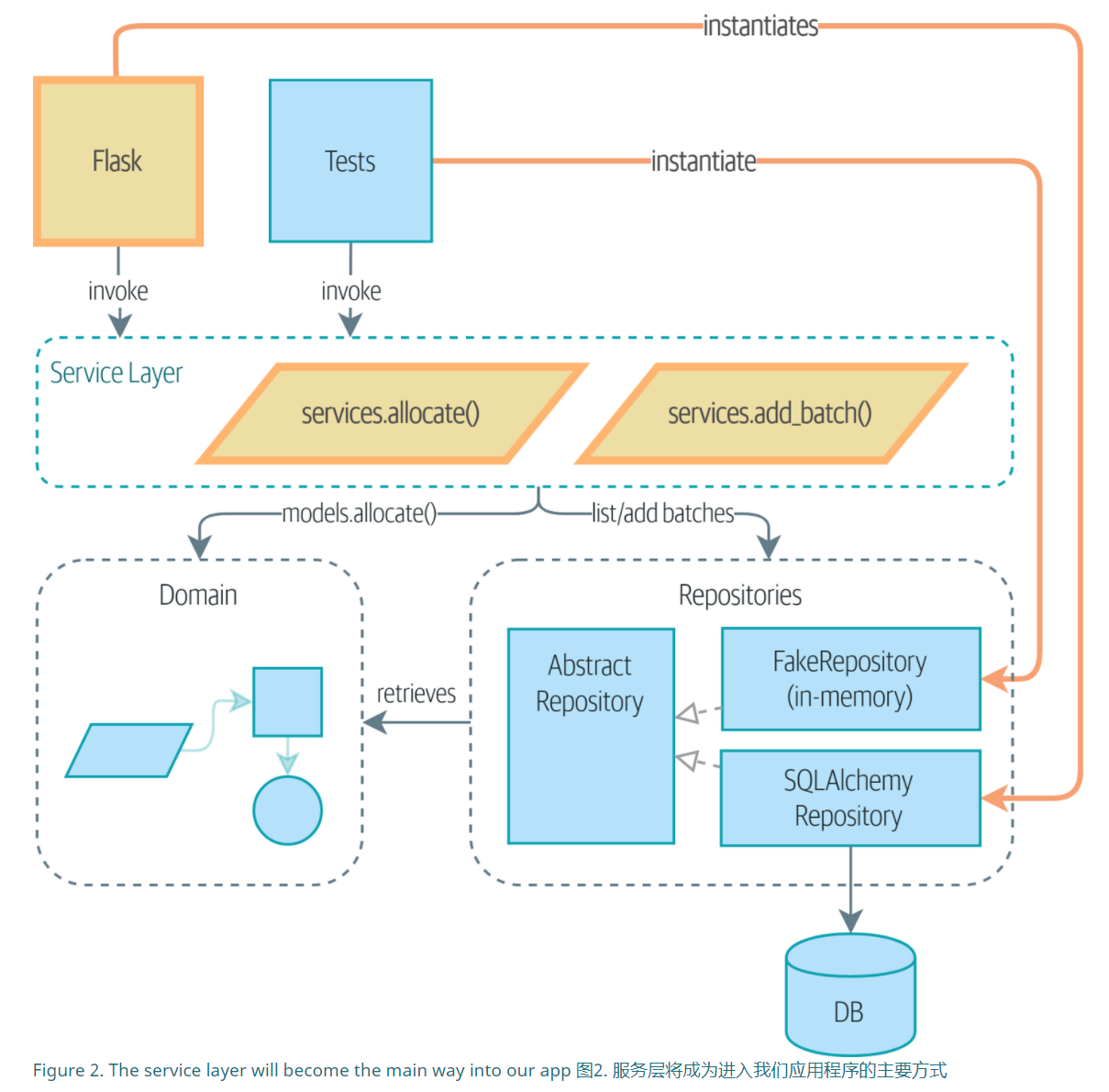
典型的服务层功能有类似的步骤:
- 从repository中提取对象
- 对请求进行检查或者断言
- 执行domain模型中的函数
- 当一切正常,保存或者更新
为什么要加入这一层?
- 因为在没加入这一层的时候,做e2e的测试复杂。
- 加入这一层后,展示层只需要负责简单的调用逻辑,而服务层则负责将所需内容编排起来。
TDD 在高速档和低速档
测试应该帮助我们大胆地改变我们的系统,但是我们经常看到团队针对他们的领域模型编写了太多的测试。当他们改变他们的代码库并发现他们需要更新数十甚至数百个单元测试时,这会导致问题。
我们用的比喻是“换档”。出发时,自行车需要挂低挡,这样才能克服惯性。一旦我们出发并开始跑步,我们可以通过换上高速档来提高速度和效率; 但是如果我们突然遇到陡峭的山坡或者因为危险而被迫减速,我们会再次降到低速档,直到我们可以再次加速。
也就是说在当需要理清楚域模型的特性的时候,使用低速挡来前进。当域模型比较稳定,需要添加新的特性的时候,那么就用高速档,在服务层进行测试。
所谓的依赖关系,就是要引入并且手动的实例化对象。
一般来说,如果您发现自己需要在服务层测试中直接执行域层的工作,这可能表明您的服务层是不完整的
每个测试倾向于覆盖一个特性的一个代码路径
理想情况下,您的应用程序的结构应该使得所有冒泡到入口点的错误(例如,Flask)都以同样的方式处理。
用原语而不是域对象来表示服务层。
工作单元 Unit of Work
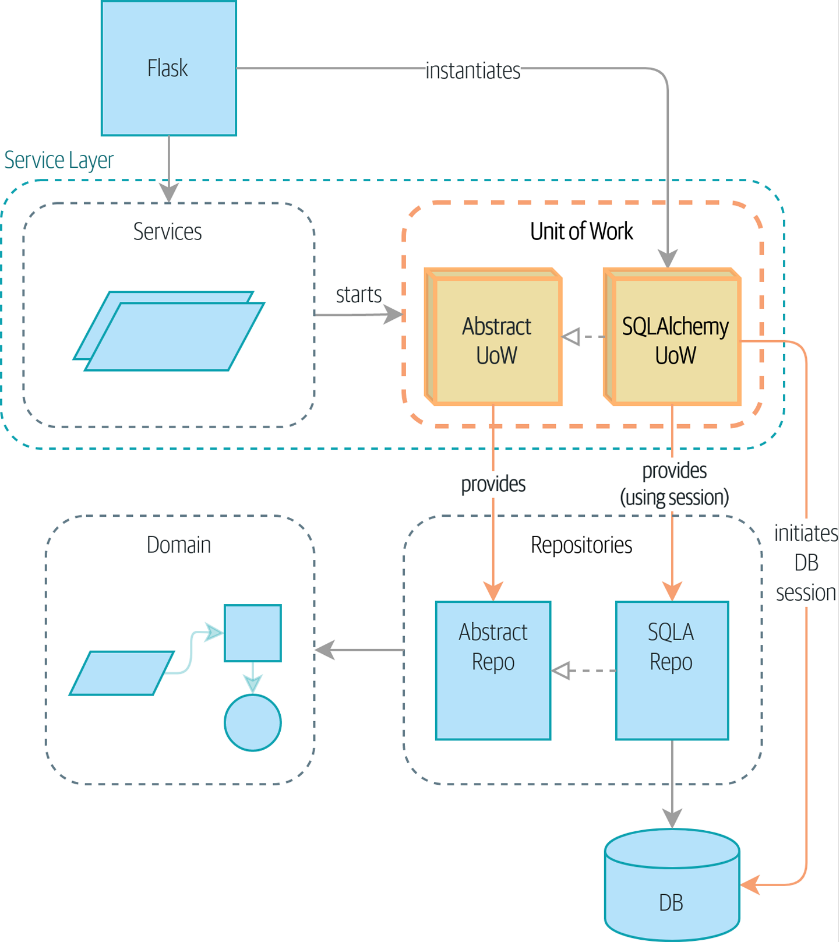
工作单元放在服务层,解决的问题是在Services中直接调用仓库还是耦合度较高,并且不易于对DB进行维护。
使用了UoW后,可以通过with uow的方式对上下文进行处理。__enter和__exit__方法
另外,将原本在server上依赖的Repository转移到了UoW上,Server只需要获得UoW就可以了。
UoW还能提供遇到异常时候的隐式处理模式:
class AbstractUnitOfWork(abc.ABC):
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type is None:
self.commit() #(1)
else:
self.rollback() #(2)
聚合和一致性边界
事实上,大量的业务流程都是通过电子邮件手工来回发送电子表格来实现的。这种“ CSV over SMTP”体系结构的初始复杂度较低,但由于难以应用逻辑和维护一致性,因此往往不能很好地进行伸缩。
聚合、有界上下文和微服务
从本质上讲,这是对试图将整个企业纳入单一模式的反击。顾客这个词对于销售、客户服务、后勤、支持等等方面的人来说意味着不同的东西。在一个上下文中需要的属性在另一个上下文中是不相关的; 更有害的是,同名的概念在不同的上下文中可能有完全不同的含义。与其试图构建一个单一的模型(或类或数据库)来捕获所有的用例,不如使用多个模型,围绕每个上下文划定界限,并明确地处理不同上下文之间的转换。
也就是所,通过对上下文的限制,确定每一个聚合的服务对象确保是最小单元的,域模型应该只包含执行计算所需的数据。例如:
Product(sku, batches) 和 Product(sku, description, price, image_url, dimensions, etc…)
聚合是进入域模型的入口点
聚合的任务是能够在不变量应用于一组相关对象时管理有关不变量的业务规则。检查其职权范围内的对象是否相互一致,是否符合我们的规则,并拒绝可能违反规则的更改,这是总体的工作。
事件和消息总线
举例:当需要使用send_mail来通告的时候,这个方法放在哪里呢? 可以想到放在现有的哪个位置都是不好的,因为违反了单一责任原则。
我们的模型不会关注电子邮件,而是负责记录事件。我们将使用消息总线来响应事件并调用新的操作。
messagebus属于服务层。
具体的操作就是在repository中添加要观察的类,然后在uow要commit的时候将所有的event传递给messagebus
def handle(event: events.Event):
for handler in HANDLERS[type(event)]:
handler(event)
def send_out_of_stock_notification(event: events.OutOfStock):
email.send_mail(
"stock@made.com",
f"Out of stock for {event.sku}",
)
HANDLERS = {
events.OutOfStock: [send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
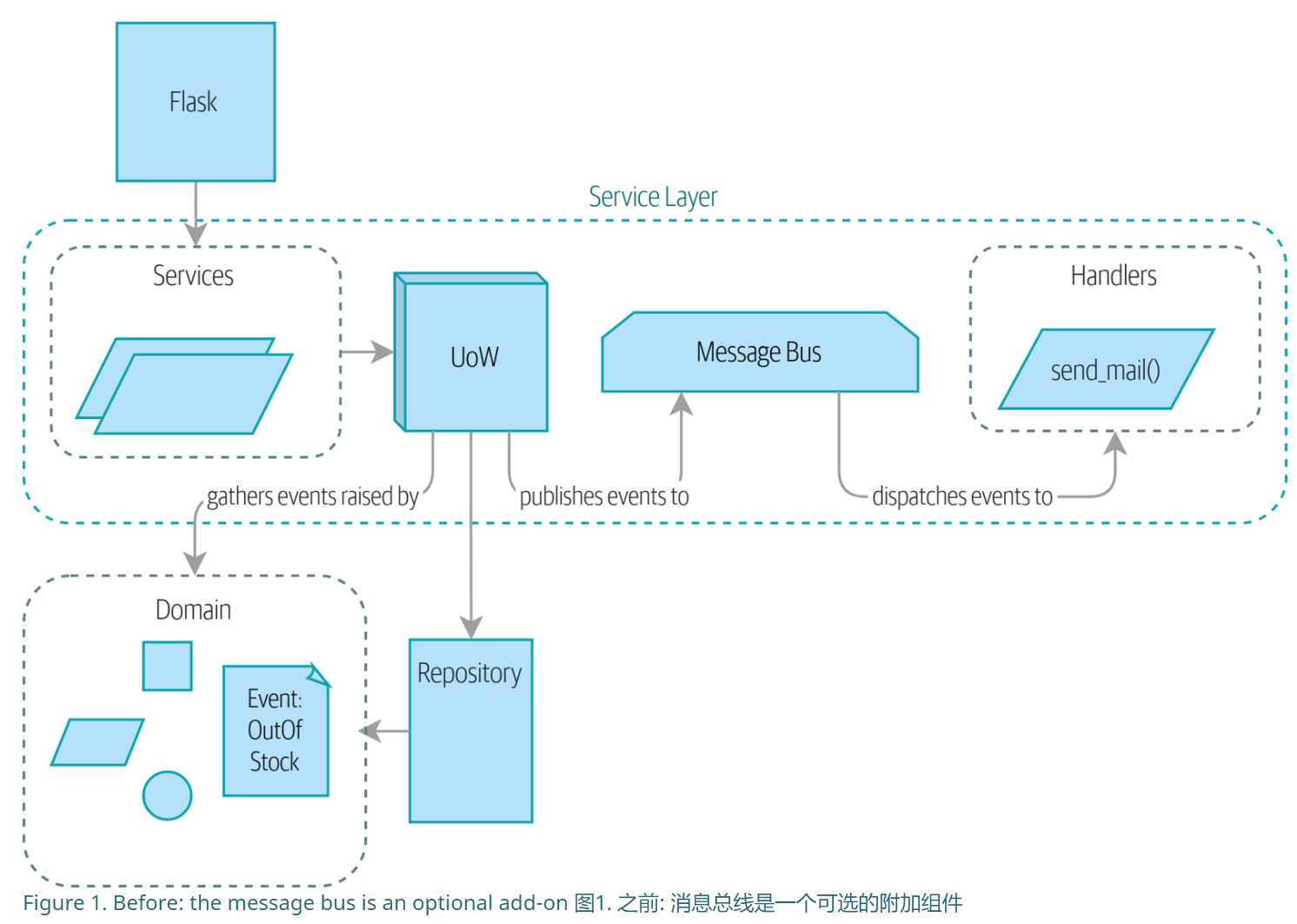
Going to Towm on the Message Bus
这一章将API调用和内部消息都统一起来了放在了前端。所有API的调用都是以消息的方式进行的。
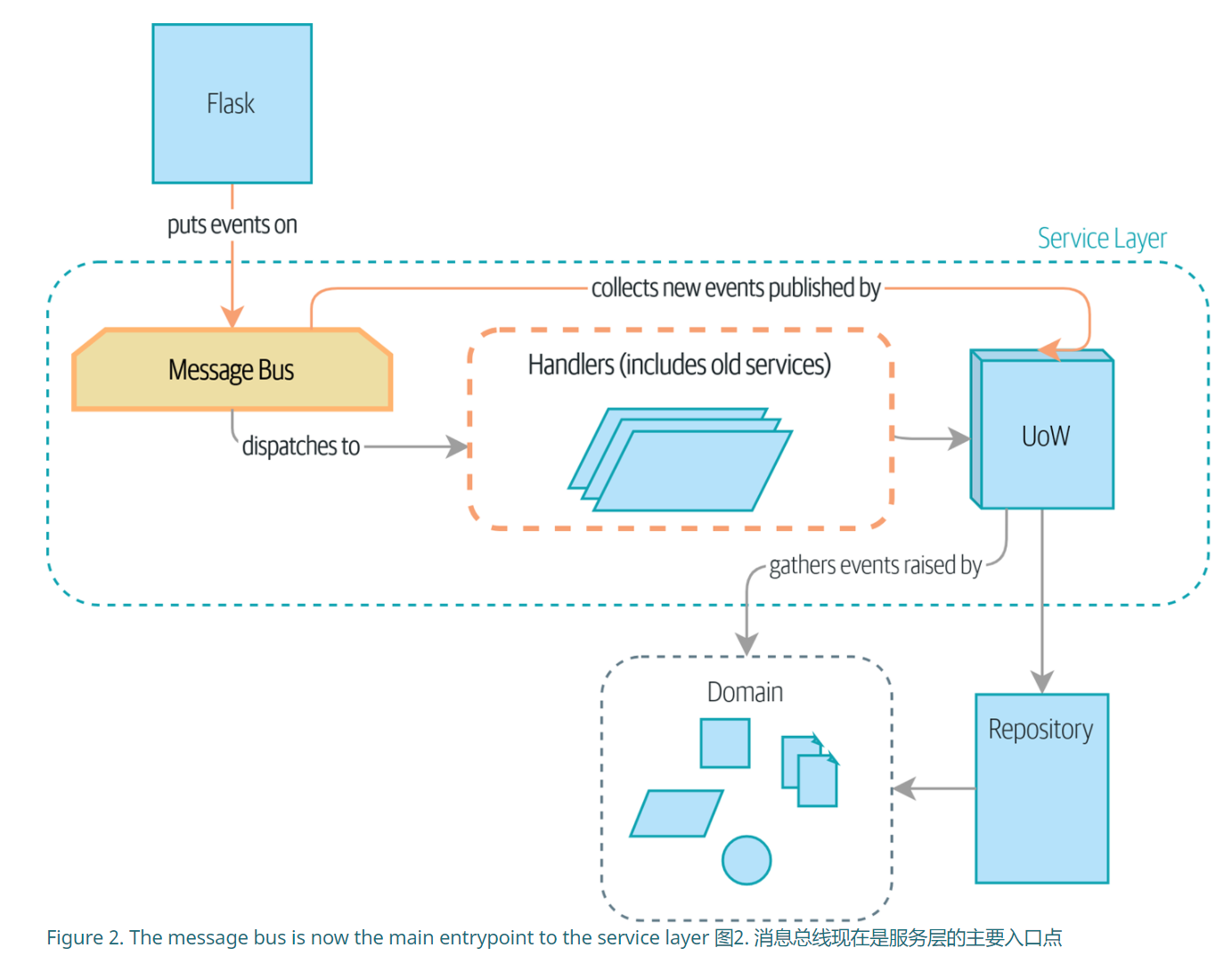
这样做也导致了整个串联关系没有了实体,只能通过日志来进行调试。
下图是时序图,在调用了BatchQuantityChanged事件后,在messagebus.py中将消息转化成了函数调用,去执行domain中的内容,然后domain又激发了AllocationRequired消息,handler接受到了后继续执行。
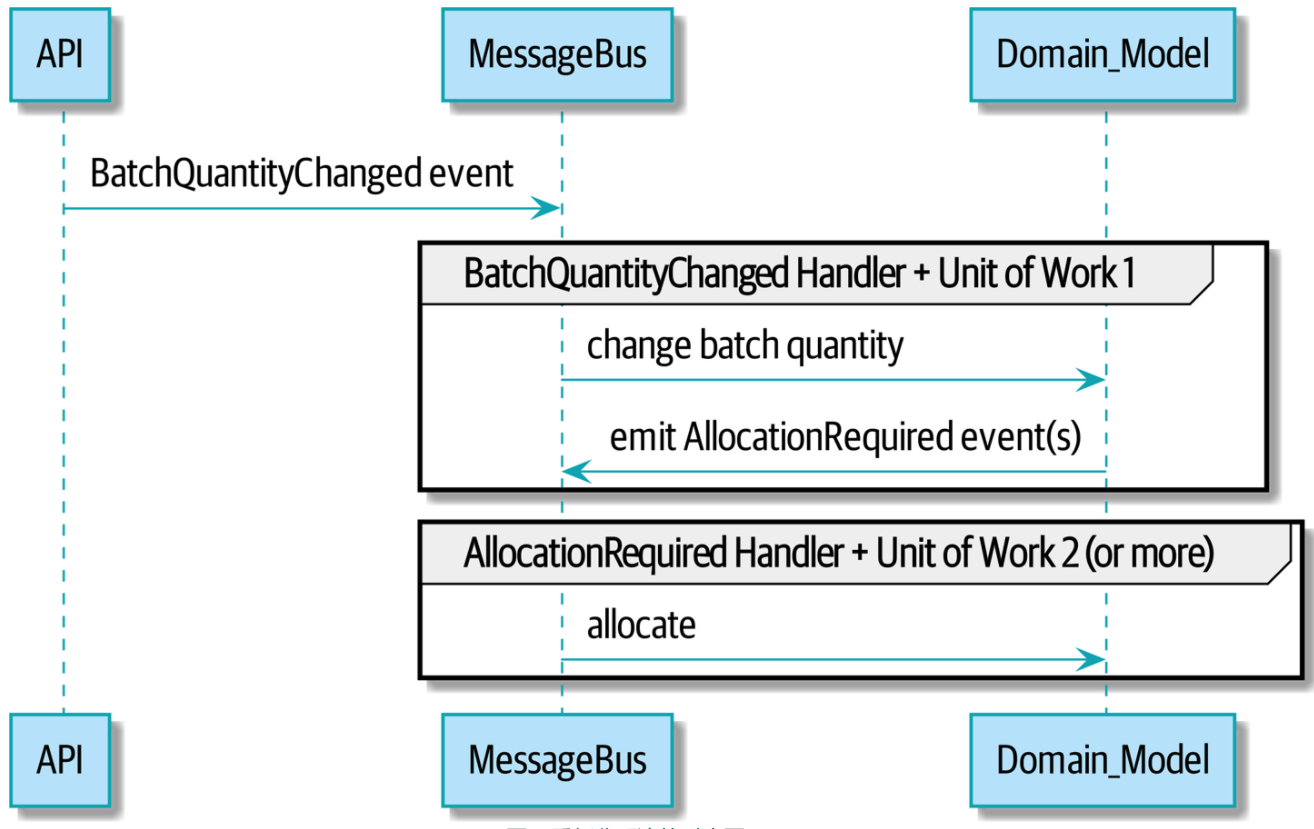
另外在做测试的时候,可以使用FakeMessageBus来进行。
命令和命令处理程序
将Event和Command分开
Event:
- 事件传递给可以委托给每个事件的多个处理程序的调度程序。
- 它捕获并记录错误,但不允许错误中断消息处理。
- 没有返回值
Command:
- 命令调度程序期望每个命令只有一个处理程序。
- 如果出现任何错误,它们很快就会失败,并且会冒出来。
Event 命名是过去时,而Command是现在时。
区别对待Event和Command有助于帮助我们理解哪些事是必须成功的,哪些是可以失败的。
from tenacity import Retrying, RetryError, stop_after_attempt, wait_exponential #(1)
...
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
for handler in EVENT_HANDLERS[type(event)]:
try:
for attempt in Retrying( #(2)
stop=stop_after_attempt(3),
wait=wait_exponential()
):
with attempt:
logger.debug("handling event %s with handler %s", event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except RetryError as retry_failure:
logger.error(
"Failed to handle event %s times, giving up!",
retry_failure.last_attempt.attempt_number
)
continue
上面的重试方法使event有一定的韧性。
Event-Driven 架构
事件驱动架构,当遇到需要与其他软件系统进行协作的时候,直接调用软件的方法相当于是强耦合了,这里给出的方式是通过异步消息来串联,使用的工具是Redis
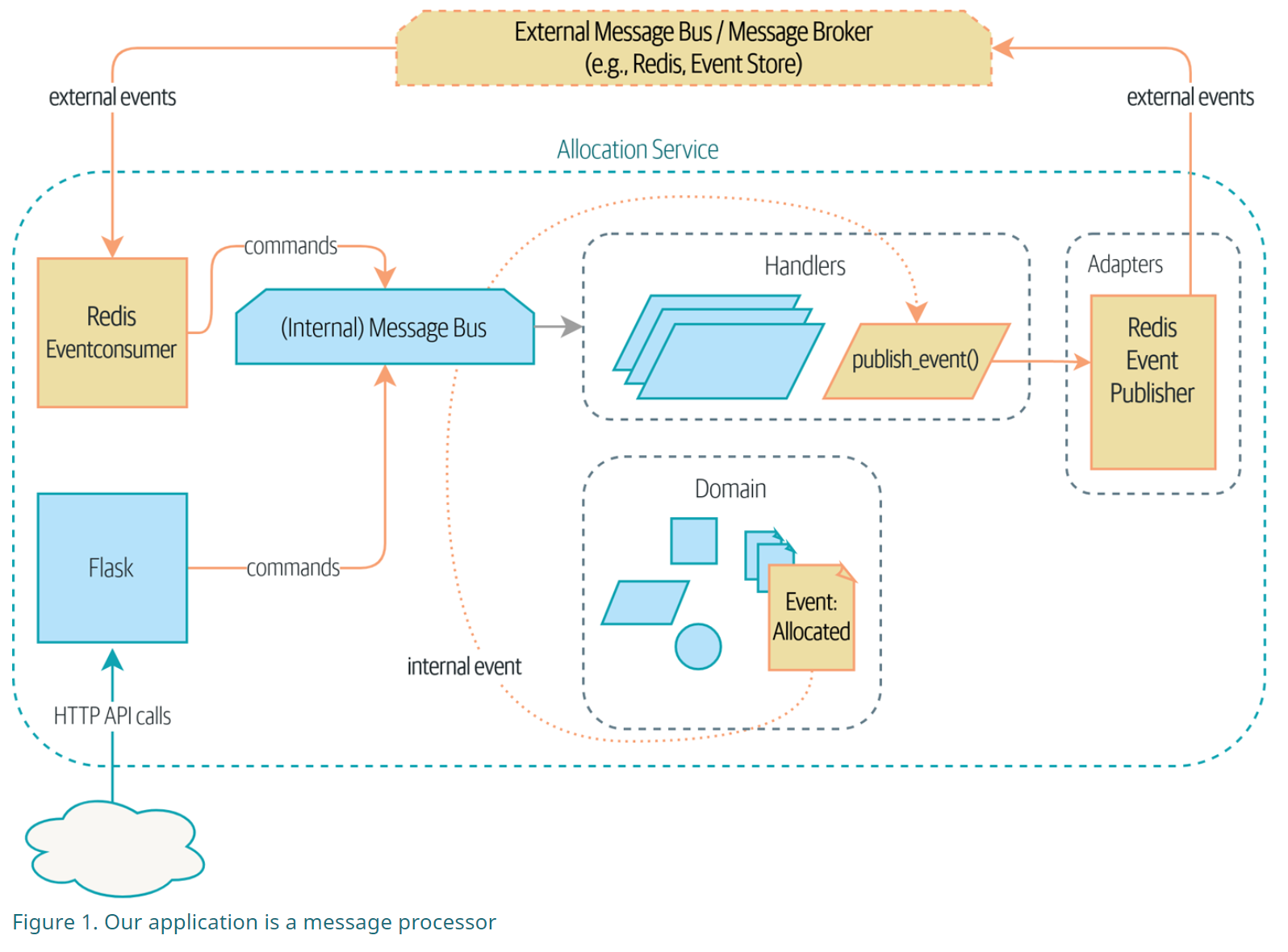
命令查询责任分离(CQRS)
command-query Responsibility separation (CQRS)
将命令与查询的责任分开。
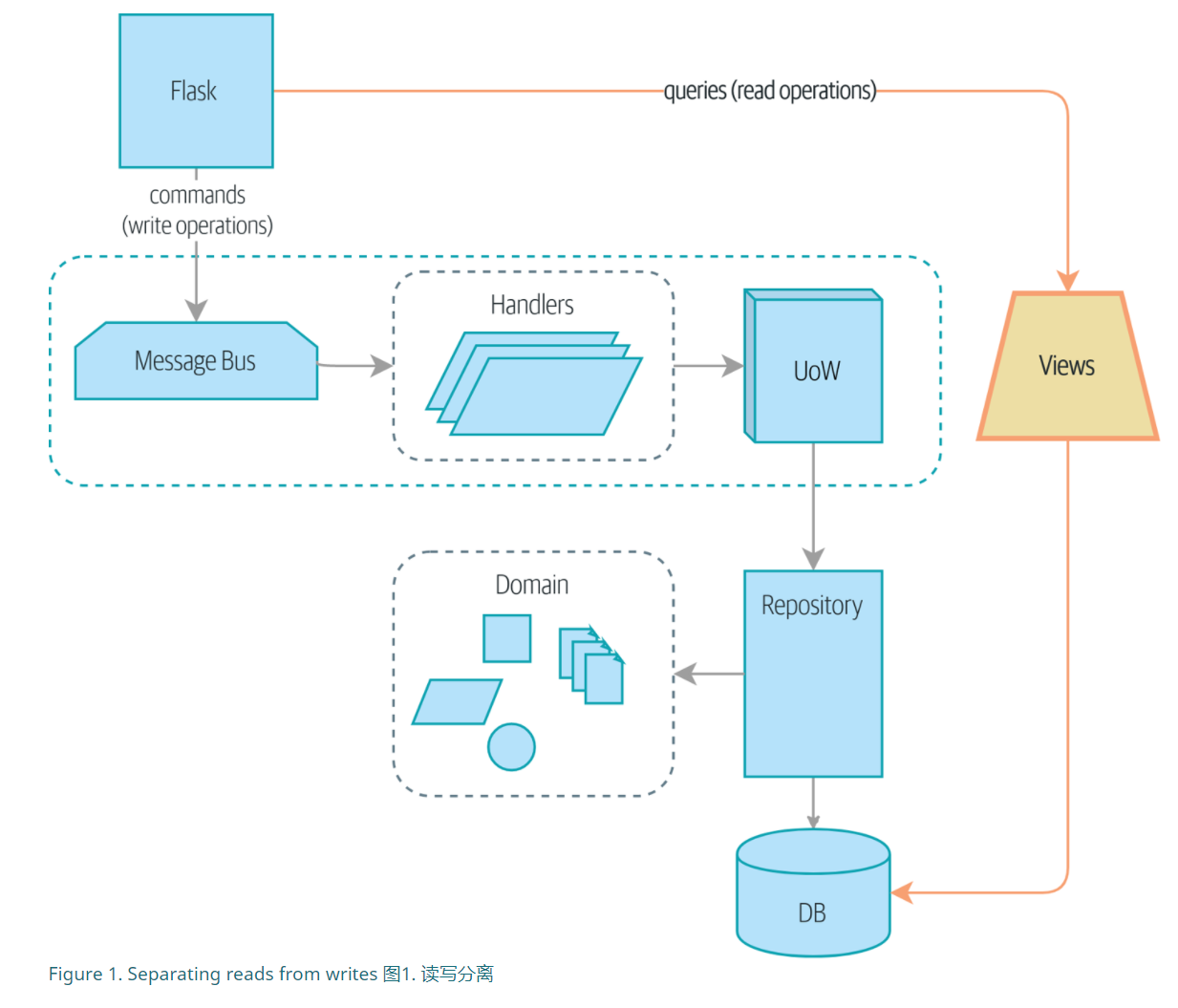
单独开辟一个view.py层作为对外的读取接口,并直接调用SQL语句进行查询,查询的是allocations_view表。
书中加入了event.Allocated事件方法handlers.add_allocation_to_read_model,将单独的给DB中allocations_view表添加可读信息。这样将外部的可读与可写的分开了。
注入依赖
所谓的注入依赖,就是将原本在方法内完成的实例化由第三方外部完成,然后传递进来的就只是实例即可。
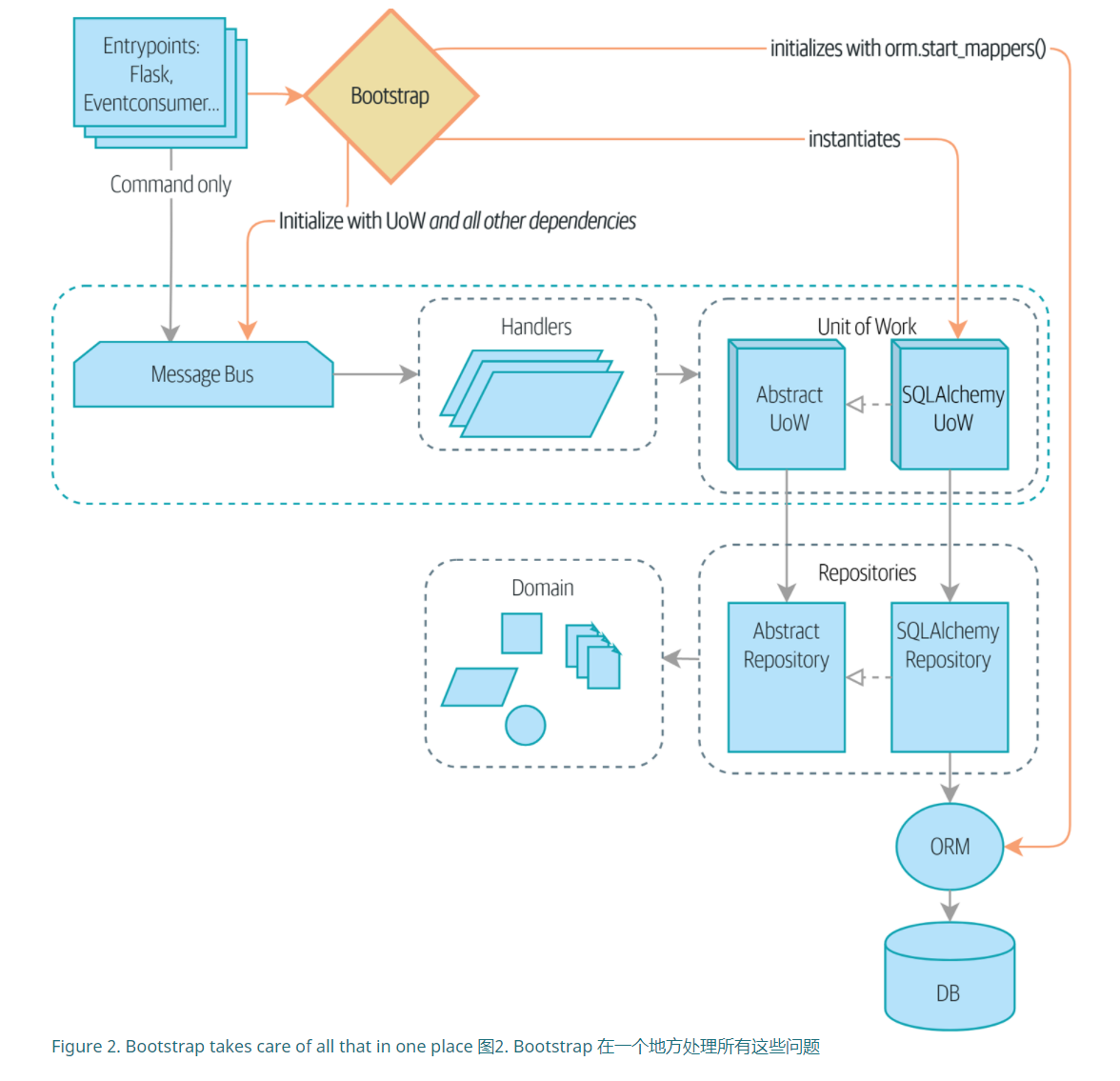
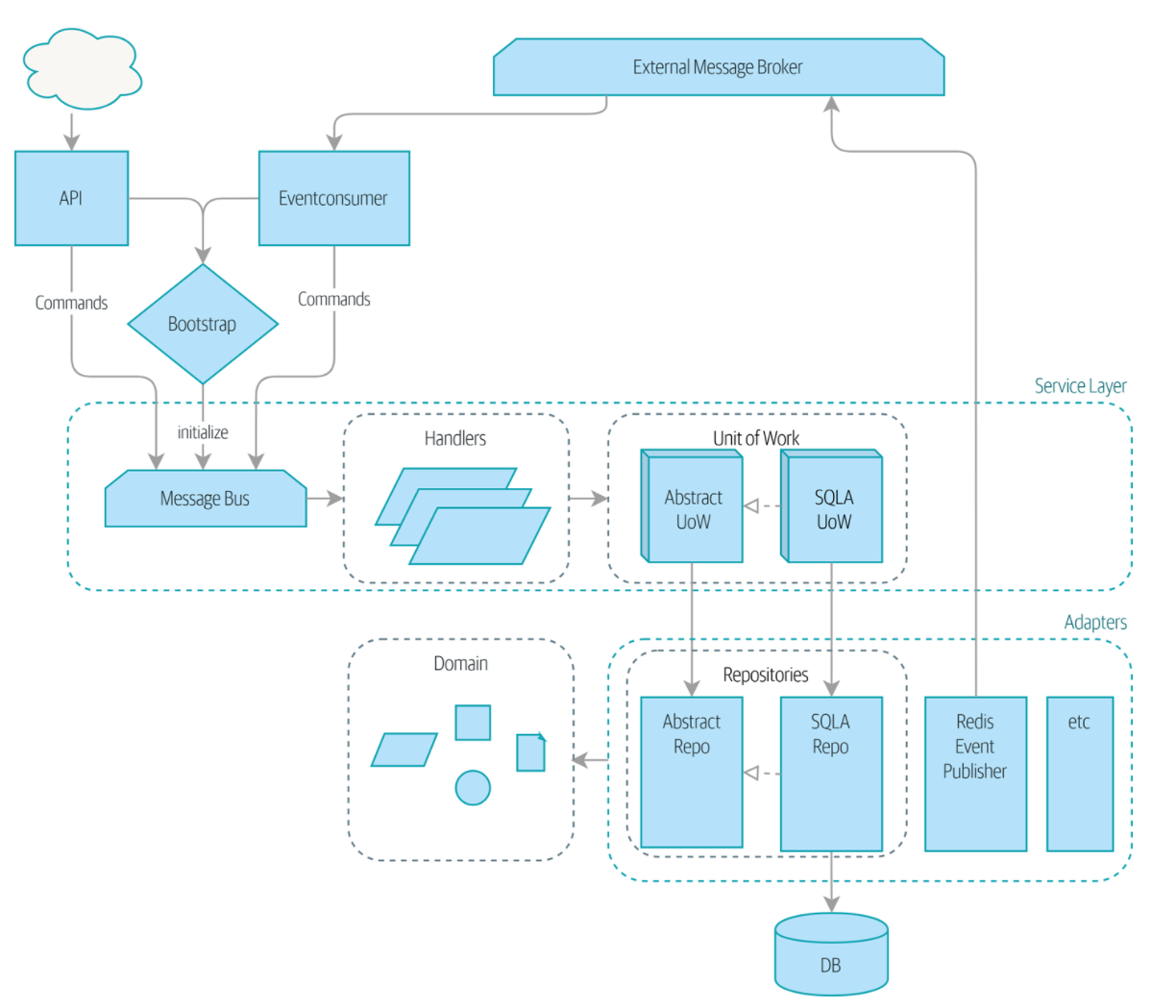
原先的MessageBus需要在内部进行组装,而这章加入了引导模块(bootstrap)。并在其中进行组装,使用lambda函数将函数预先封装好。后面直接调用,而不用获取uow等上下文环境。
加入了引导模块的好处是可以根据实际的情况进行拼装,比如测试还是生产。
后记
在本书的开头,我们说过一个大泥球的主要特征是同质性: 系统的每个部分看起来都是一样的,因为我们没有明确每个部分的责任。为了解决这个问题,我们需要开始划分责任并引入明确的界限。我们可以做的第一件事情是开始构建服务层(协作系统的领域)。
前面我们说过,我们希望避免代码中混杂无关的细节。特别是,我们不希望在域模型中进行防御性编码。相反,我们希望确保在域模型或用例处理程序看到请求之前,请求已知是有效的。这有助于我们的代码在长期内保持整洁和可维护性。我们有时将此称为在系统边缘验证。
验证是验证什么?句法、语义和语用(syntax, semantics, and pragmatics)。
在系统边缘进行验证。
语法的验证
通过schema模块对command.py模块中的dataclass进行验证。
这样就可以保证在api和业务核心上的代码干净。
from schema import And, Schema, Use
@dataclass
class Allocate(Command):
_schema = Schema({ #(1)
'orderid': int,
sku: str,
qty: And(Use(int), lambda n: n > 0)
}, ignore_extra_keys=True)
orderid: str
sku: str
qty: int
@classmethod
def from_json(cls, data): #(2)
data = json.loads(data)
return cls(**_schema.validate(data))
这样做有个弊端就是要声明两次。
语义验证
将规则验证单独提取出来,开辟单独的Exception,并在MessageBus中捕获
语用
语用就是结合上下文,书中没有给出示例。
验证语法可以发生在消息类上,验证语义可以发生在服务层或消息总线上,验证语用属于域模型。
全书的最终结构:
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 365433079@qq.com